A privacy gateway between you and the closed models.
OSSRedact sits in front of any LLM you do not control. It detects and redacts personal data on the way out, then rehydrates the model's answer on the way back -- so real values never cross the wire, and you still get a useful response.
Redact on the way out. Rehydrate on the way back.
Clean text passes straight through. PII-bearing text is redacted to typed placeholders on your machine, and only those placeholders cross the wire. On the way back, OSSRedact rehydrates the model's response to the real values, losslessly.
your tool
App, agent, or LLM client
on your machine
The OSSRedact gate
any LLM API
The cloud sees placeholders
A trained model, on a floor that never lifts.
A single model is the wrong bet for a privacy gate. Recall in the high nines is excellent, and still not good enough for the categories where one miss is catastrophic. So the model does not work alone.
The neural model reads context and finds the open-ended PII -- names, addresses, and free text that no rule can enumerate.
The deterministic floor sits underneath, always on. Secrets and structured identifiers are matched and validated by rule, so the catastrophic categories are caught with certainty, not probability.
Catches the open-ended categories a rule cannot describe.
recall in the high nines · excellent, and by nature below 100%
Rules and validators for the categories where a single miss is unacceptable.
4,365 / 4,365 injected secrets caught · 0 decoy false positives
Two open-weight models. One scheme.
Every checkpoint is published on open weights and shares the same 20-label scheme, so you can choose more recall or a smaller footprint without changing how the gate behaves. The base model ships by default.
xlm-roberta-large
recall 0.9964
The most accurate checkpoint, for when recall matters more than a small footprint.
xlm-roberta-base
recall 0.9932
The shipped tier. Near-identical recall to the large model (0.9932 vs 0.9964), at half the parameters.
1.7 ms
clean fast-path, no PII
23.5 ms
PII-bearing request
~42 ms
CPU INT8 detection, fully local
One scheme, twenty labels.
Each detection carries a typed label, split into two tiers by how much a miss costs.
Higher recall, far fewer false positives.
Recall is the leak-prevention rate: did a detected span actually cover the sensitive value. Measured on held-out Quebec FR/EN sets against Microsoft Presidio (English + French large models, same sets, same metric).
0.9964
full-stack detection recall on a 7,498-row held-out set (0 train overlap)
12/ 7,498
over-redactions on clean text. Microsoft Presidio: 343 to 508
+17pts
higher recall than Presidio on the ALL-CAPS gate (up to +23 elsewhere)
~42ms
CPU INT8 detection, fully local. The deployed base model nearly matches the large model's recall at half the parameters
v11 held-out recall: 0.9964 (large, 559M) and 0.9932 (base, 277M). French recall 0.980, English 0.978. Models are trained on synthetic Quebec data and validated against a real-Quebec corpus. The Presidio comparison uses the historical v6/v7 sets, where Presidio logged 343 or more false positives to our 0.
218,931
PII spans redacted across 5,000 synthetic French and English documents, with zero errors.
Built and validated entirely on the local gate, measured against ground truth. Real documents never touch a cloud model.
catastrophic leaks on the held-out run
- 0 email leaksclear
- 0 SIN leaksclear
- 0 account or card leaksclear
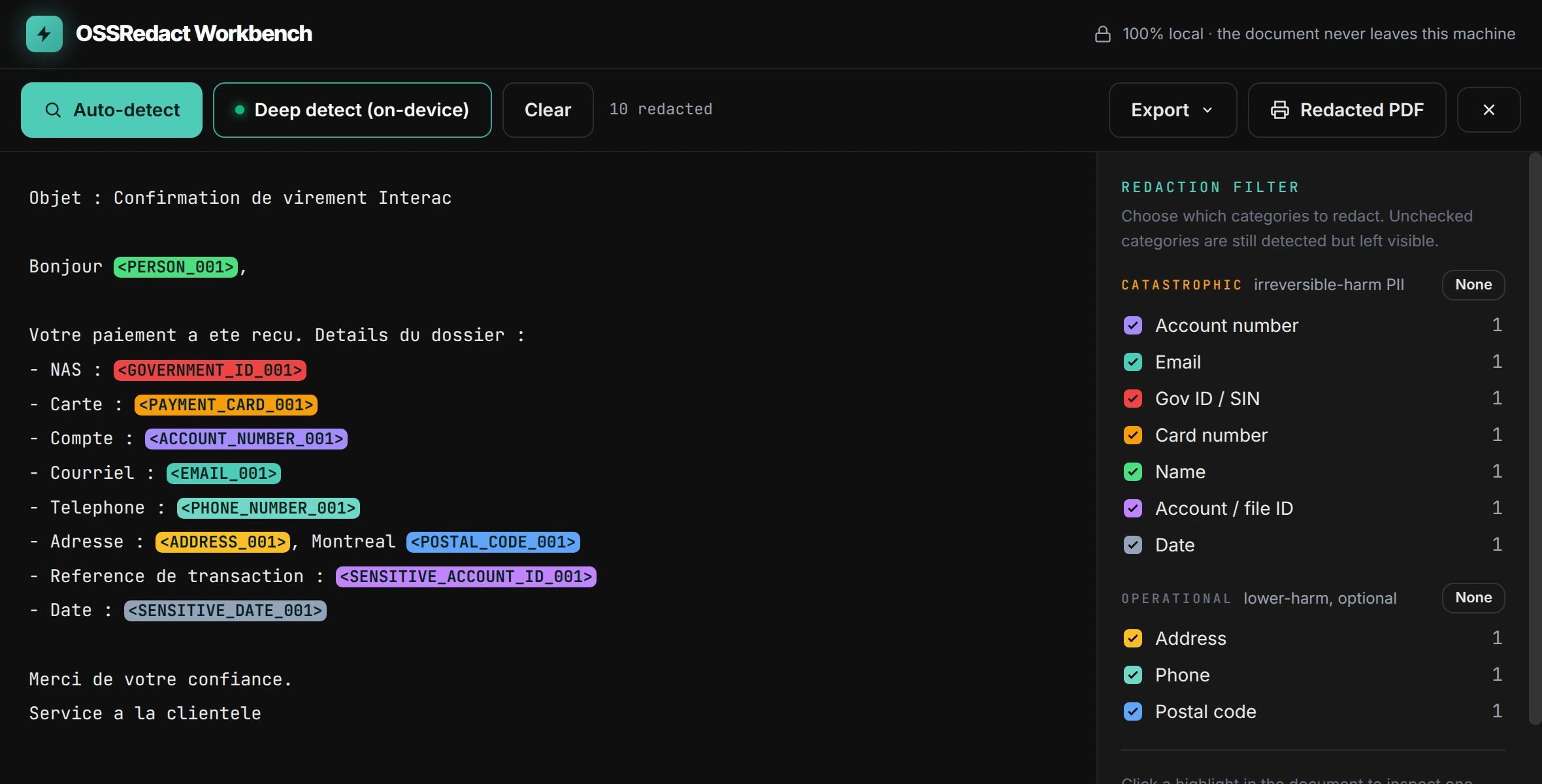
A local app, with review before redact.
The gateway runs headless, but the workbench is where you see it work: detect a whole document, inspect every span, then redact only what you approve.
Drop in a document
Point the app at a file -- PDF, Word, Excel, CSV, or text. Tier-0 runs instantly; deep detect adds the on-device model.
Review every span
Each detection is shown with its label and source before anything changes. Approve, edit, or add a manual span.
Nothing is uploaded
Detection and redaction happen on your machine. The document never leaves it, with or without a network.
Point the tools you already use at it.
The workbench is where you watch it work. The gateway is the headless version: a local proxy that sits in front of any cloud model. Set one base URL and your existing tools route through it -- redacted on the way out, rehydrated on the way back, with a receipt for every request.
Two clients, today
Same redact and rehydrate contract for both, through the adapters the gateway serves today: Anthropic /v1/messages and OpenAI /v1/responses. Your auth header is forwarded verbatim, so your existing login is honored and the cloud bill stays where it was.
“...client SIN 046 454 286, call back 514-555-0188 to confirm the balance.”
“...client SIN <GOVERNMENT_ID_001>, call back <PHONE_NUMBER_001> to confirm the balance.”
“...the note lists SIN 046 454 286 and a callback at 514-555-0188.”
What it does not do yet.
No detector is perfect, and a privacy tool that pretends otherwise is the dangerous kind. Here is where OSSRedact falls short today.
- Models are trained and validated on synthetic Quebec data. Broader domains are future work.
- Names glued into code identifiers are under-detected (0.882 recall on that slice).
- A bare long digit run sitting right next to letters can be missed.
- French and English only, by design.
- Recall is below 100%, so the deterministic Tier-0 layer is the reliable floor for the catastrophic categories: secrets, cards, and SIN.
License: the gate, the workbench, and the model weights all ship under the MIT license. Read it, run it, fork it.
Real values out, tokens in -- before anything is sent.
Paste your own text and watch the swap happen, with an empty Network tab.